
MTCNN全称 “Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks”,采用级联网络的思想将人脸检测和人脸对齐放在一起进行。总的来说,MTCNN可以分为三个子网络P-Net, R-Net和O-Net,每个网络都要做人脸分类、bounding boxes预测以及人脸关键点(landmarks)的定位,但只在O-Net输出关键点。
1. 网络结构

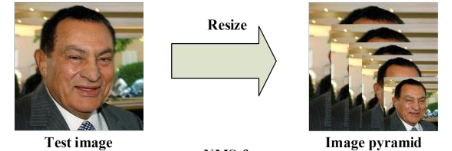
1.1 图像金字塔
对于每一张输入图片,MTCNN都会对其进行缩放以构成一个图像金字塔,这些不同大小的图片作为后续级联网络的输入,以提高模型对不同大小的人脸的检测能力。
1.2 P-Net
P-Net(Proposal Network)是一个全卷积网络(Fully Convolutional Network),采用结构较为简单的网络提取图片特征和标定边框,并通过bounding box regression和NMS对边界框进行调整得到一系列人脸候选框。这有点类似于two-stage detector的候选框proposal环节。
P-Net中最后一个卷积层的输出被分为2个分支,分别经过Conv4-1和Conv4-2,Conv4-1的输出经过Softmax之后得到某个bounding box区域属于人脸类别的置信度,Conv4-2直接输出bounding boxes坐标。
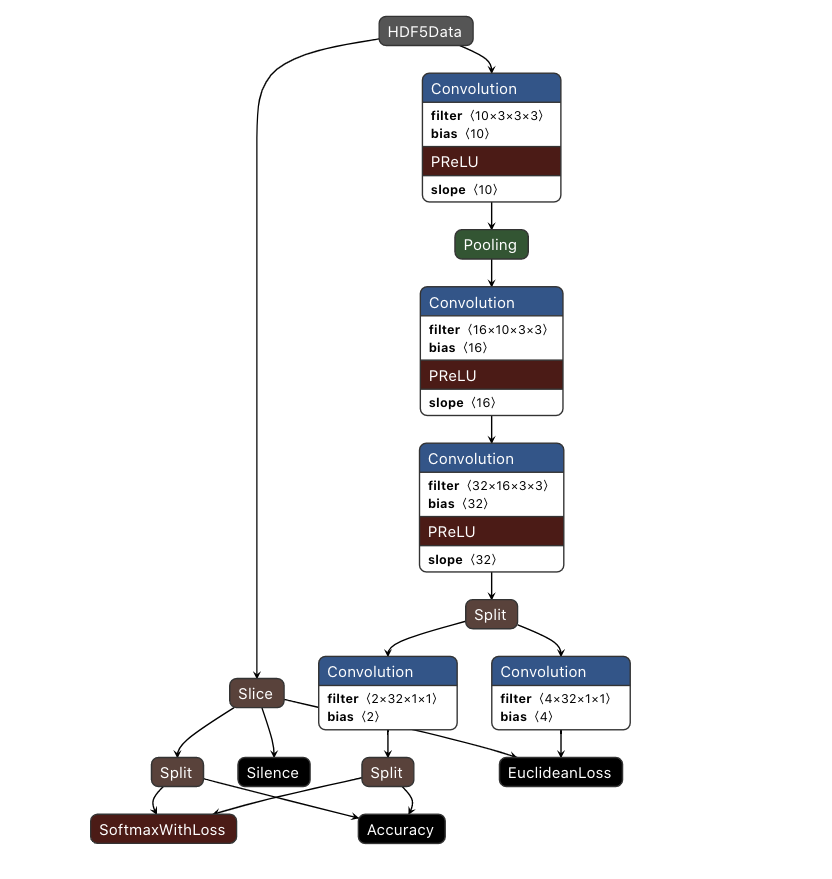
论文中给出的P-Net的第三个卷积层之后其实是分成了三个分支,分别预测类别,回归边框以及预测面部关键点的位置,但是在作者GitHub的代码里面却只有两个分支,没有计算面部关键点的位置。猜想这样做的原因是P-Net对面部关键点位置的计算可能并没有太大帮助,同时,取消这一步还能提高P-Net的运算速度。
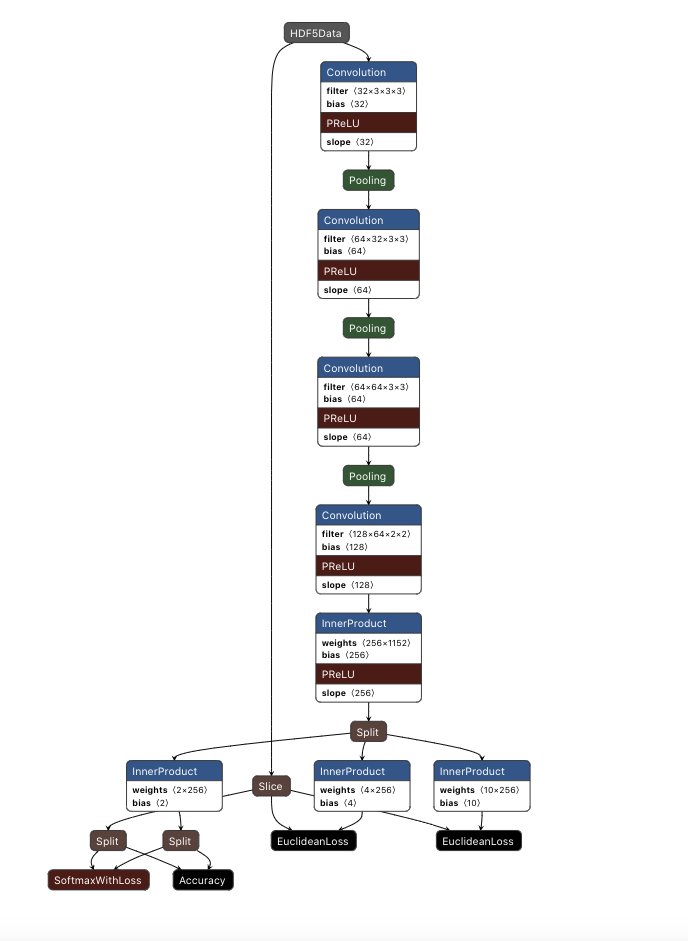
1.3 R-Net
R-Net(Refine Network)与P-Net类似,但是相比于P-Net来说,其增加了一个全连接层。R-Net接收P-Net的输出作为输入,进一步滤除效果较差的候选框,对剩余的候选框采用bounding-box regression 和 NMS进一步优化结果。

P-Net中全卷积的输出是$1\times 1\times 32$的特征图,R-Net在全卷积后通过一个$128$的全连接层,能够保留更多的图像特征,加上R-Net的输入是具有一定可信度的候选框,这样能够为O-Net提供更高准确度特征。
1.4 O-Net
O-Net(Output-Network)相比于R-Net增加了一个卷积层,最后的全连接层换成了256,能够更为精确的判别候选边框和定位人脸关键点。
2. 训练过程
2.1 损失函数
2.1.1 人脸分类
人脸检测中的分类其实是属于二分类问题,论文中采用交叉熵损失(cross-entropy loss),对于样本$x_{i}$,有如下定义:
其中,$p_{i}$是网络输出的候选框是人脸的概率,$y_{i}^{det}\in \{0, 1\}$是第i个样本的标签。
2.1.2 边界框回归
对于每个候选框,网络预测的是其与最近的真实边框的坐标偏移。边界框回归采用的是欧几里德损失(Euclidean loss):
其中,$\hat{y}_{i}^{box}$是网络输出的边框坐标,$y_{i}^{box}$是真实的边框坐标,$y_{i}^{box}\in R^{4}$ (left top, width, height) 。
2.1.3 面部关键点定位
面部关键点的定位也是采用回归的方法,同样采用Euclidean loss:
其中,$\hat{y}_{i}^{landmark}$是网络输出的5个关键点的坐标,$y_{i}^{landmark}$是真实的关键点坐标,$y_{i}^{landmark}\in R^{10}$ (left eye, right eye, nose, left mouth corner, right mouth corner) 。
2.2 多源训练
每个网络都有各自的任务,训练的时候也是输入不同的图片,所以在训练过程中有些损失函数会暂时不用。例如,当处理只有背景(无人脸)的照片时,MTCNN只计算分类的损失$L_{i}^{det}$,其余两个损失不计算。所以总的损失函数表示为:
其中,N是训练的样本总数;$\beta_{i}^{j}\in \{0, 1\}$ 是样本类型的指示标志,对于特定类型的训练样本,消除某个损失函数的影响;$\alpha_{j}$表示某个任务的重要性,论文中用的值如下所示。
| Network | $\alpha_{det}$ | $\alpha_{box}$ | $\alpha_{landmark}$ |
|---|---|---|---|
| P-Net | 1 | 0.5 | 0.5 |
| R-Net | 1 | 0.5 | 0.5 |
| O-Net | 1 | 0.5 | 1 |
2.3 困难样本挖掘
文中提出的困难样本挖掘也是本文的一大亮点。那么什么是困难样本挖掘呢?困难负样本是训练在模型过程中难以区分的负样本。模型通常对正样本有较高的置信度,对负样本有较低(接近于0)的置信度,但是也难免存在一些负样本使得模型对他们那么确定。困难负样本挖掘(Hard Example Mining)就是找到这些负样本。
本文提出来的在线困难样本挖掘(Online Hard Example Mining)方法只在训练阶段的人脸分类中进行,这里的“在线”指的应该是在训练阶段同步进行。具体做法是:对于每一个训练batch中的样本,按照前向传播中计算出来的loss排序,选出前70%的样本作为困难样本。在反向传播中,只计算困难样本的梯度并用此梯度来更新参数。
2.4 训练数据
由于本文将人脸识别和对齐结合起来,在训练中一共用了4种不同的标签:
| Annotation | Rule | Usage | Percentage |
|---|---|---|---|
| Negative | IoU < 0.3 | Face classification | 0.3 |
| Positive | IoU > 0.65 | Face classification, Bounding box regression | 0.1 |
| Part faces | 0.4 < IoU < 0.65 | Bounding box regression | 0.1 |
| Landmark faces | 5 landmark’s positions | Facial landmark localization | 0.2 |
为什么要在Negative和part faces之间留0.1的IoU gap? 这部分样本属于什么类型?四种类型的比例之和并不为1,剩余部分的样本属于什么类型?
每个网络的输入数据如下:
P-Net:从WIDER FACE数据集中随机随机裁剪得到Positive, Negative 和 Part faces;从CelebA中得到Landmark faces,输入P-Net的图片尺寸是12*12*3。
R-Net和O-Net分别接收来自前一级网络输出的24*24*3,48*48*3的特征图。
3. 其他
- MTCNN卷积网络中采用的是PReLU激活函数,为带参数的ReLU函数。相比于ReLU直接滤除负值,PReLU引入参数对负值有所保留。该参数也是可学习的,允许不同的神经元具有不同的参数,这在一定程度上提高了模型的性能。
- Bounding box regression:和YOLO一样,把边界框定位看成是回归问题。在图像检测中,边界框属性包含在一个4维的向量中,表示边界框中心的坐标和宽高,在回归问题中,网络预测的是边界框中心坐标相对于ground-truth坐标的偏移量,以及边界框宽高相对于ground-truth的缩放比。这些偏差值将会用来对预测边界框进行微调。与YOLO V3不同的一点是,MTCNN没有用到anchor的思想。
- NMS:MTCNN在每一级网络都采用NMS滤除大量无效的和重合度高的候选边界框。
- 全卷积网络:在MTCNN的P-Net中采用了全卷积网络,全卷积网络是去除了传统卷积网络架构中的全连接层。全卷积网络的一个好处是可以接受任意尺寸的输入图片,采用反卷积层对最后一个卷积层的特征图进行上采样,使它恢复到输入图片尺寸。
对我的启发
MTCNN采用级联架构整合多任务卷积网络实现高精度人脸检测。在我的项目中也需要实现多任务,如果想用一个网络做到end-to-end的模型,对现在的我来说还是比较困难的。但是如果把每个任务放在特定的网络中来实现,每个网络分开训练,这种设计可能稍微容易一点,MTCNN刚好给我提供了一个思路。