
由于论文本身写得比较随意,V3里面有很多细节其实作者在论文里都没有提及,在网上看过一些文章之后,把V3里面设计的一些细节都梳理一遍,方便接下来的coding。虽然现在YOLO V4已经出了,但是YOLO V3仍然值得好好研究。
1. 网络结构
相比V1 和 V2,V3比较明显的一个改进就是backbone的结构变化,这里推荐一个开源的网络可视化工具:Netron, 支持多种网络配置格式。想看YOLO的网络结构的话直接到DarkNet网站上下载相应的 cfg 文件,导入即可。
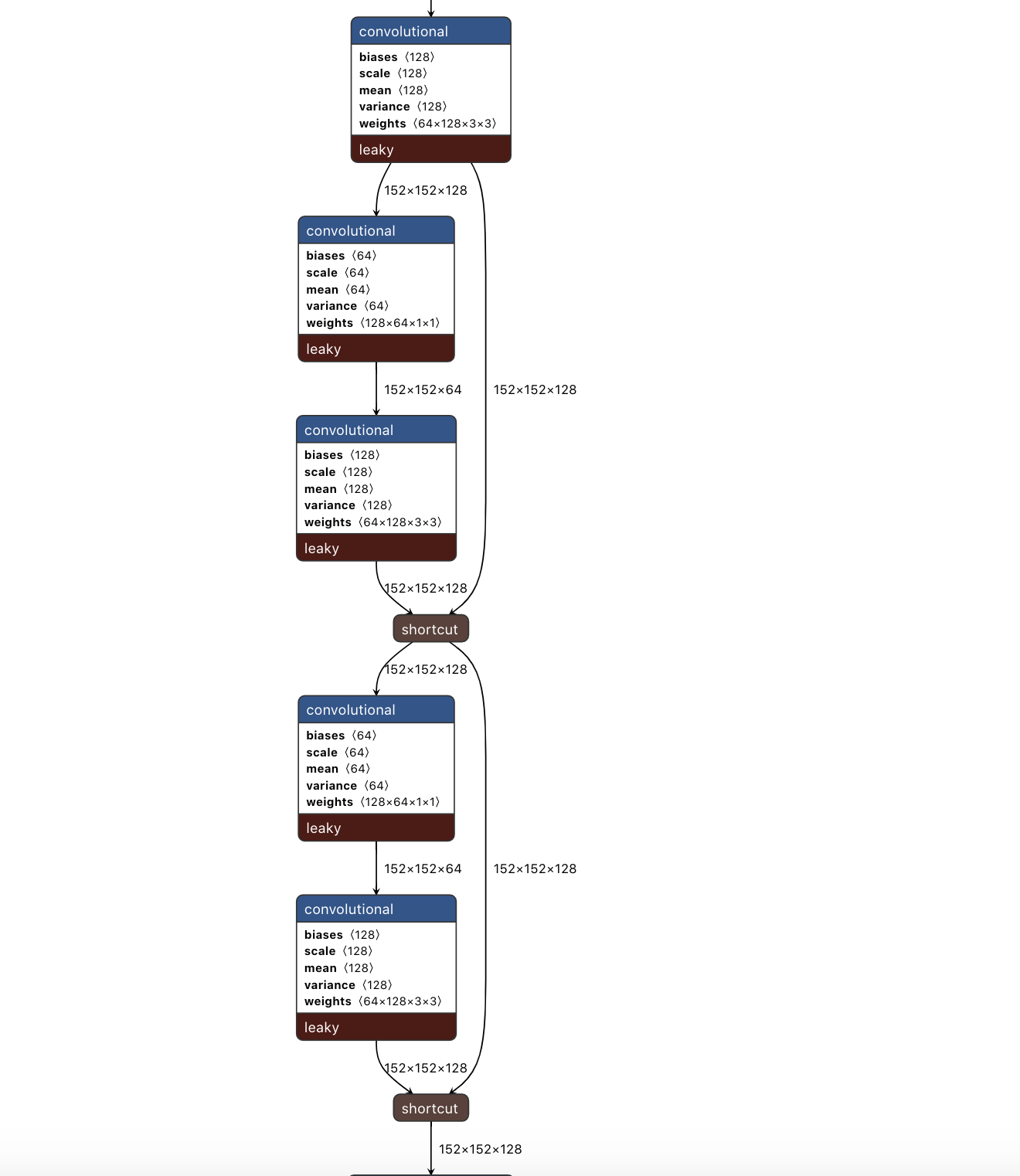
这个Netron 的图看起来还是不够直观,这里借助 木栈 大佬的图片来帮助理解V3的网络结构。

- DBL: YOLO V3网络的基本组件,从图中可以看出,DBL由Convolutional layer, Batch Normalization 和 Leaky ReLu 层组成;
- res unit:YOLO V3的新网络开始借鉴 ResNet的思想,在网络中加入残差结构。在一个res unit中有2个DBL 和一个shortcut;
- res n:这里的n表示在一个res block里面包含几个res unit,例如res 1表示包含一个res unit, res 8表示包含8个res unit,这组成立YOLO V3中的一个大组件;
add:张量相加,用于残差层。张量直接相加,不会扩充维度。例如$152 * 152 * 128$的两个张量相加,结果还是$152 * 152* 128$;
concat:张量拼接,将浅层网络的某一层和和后面某一层的上采样进行拼接。张量拼接会扩充维度,例如$26 * 26 * 256$和$26 * 26 * 512$的两个张量拼接,结果是$26 * 26 * 768$。
1.1 Backbone
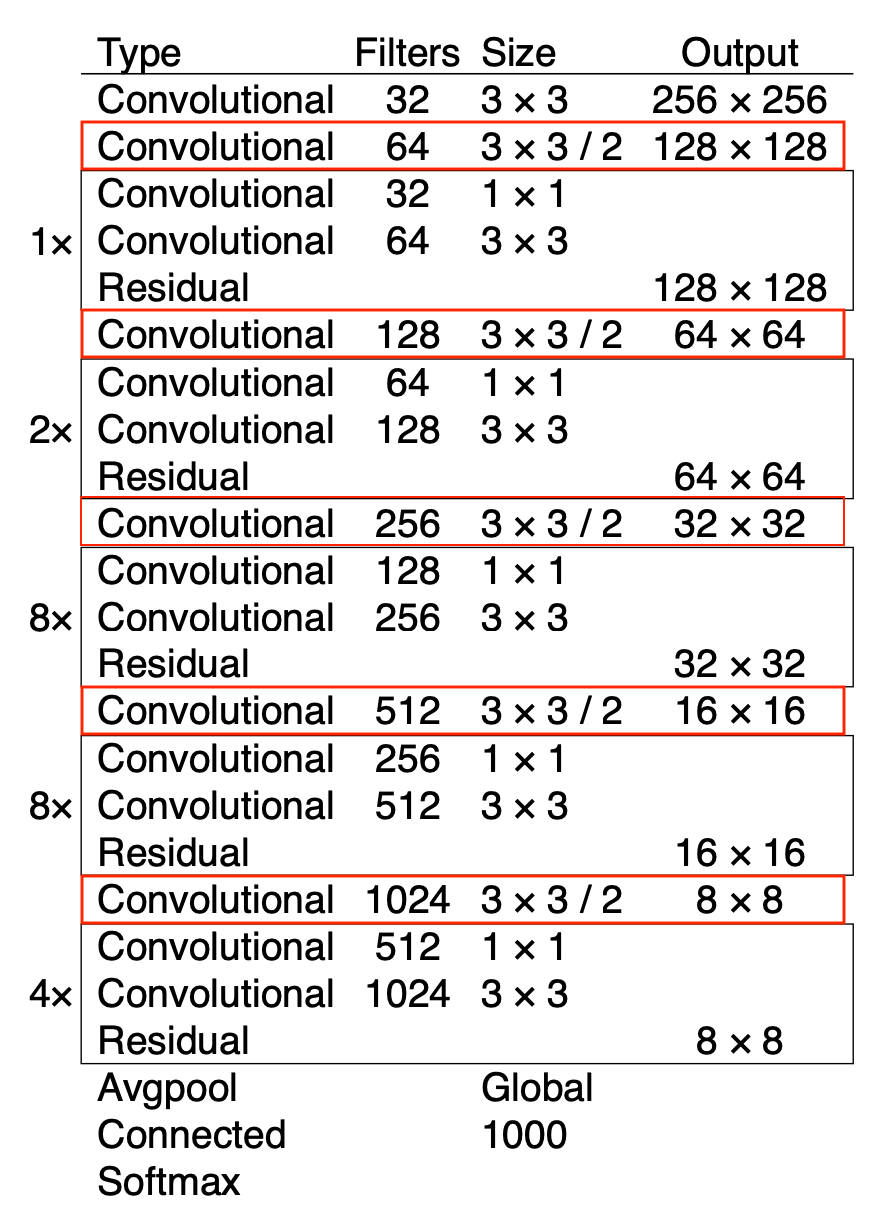
YOLO V3中的Backbone被命名为Darknet-53(如上图所示)。但是,在整个V3的网络中,没有池化(pooling)和全连接层,内部张量的尺度变化依靠卷积核的步长变化来实现,例如stride=(2,2), 可以使图像的宽和高都缩小一半。虽然在Darknet-53的最后有一个全局的平均池化,但是在V3中实际没有用到这一步。在V3中,张量的尺度变化一共有5次,这就是为什么$608 * 608$的输入,输出为$19 * 19(608/2^5)$ 的原因。
在Darknet-53中,大量使用残差结构,这样做有几个好处:
- 使网络更深了,学习能力更强了。同时,残差结构还保证了较深的网络也能够收敛;
- 残差网络中的
1*1卷积能够有效的调整每次卷积的维度,这样在一定程度上减少了参数量。
2. Prediction Across Scale
YOLO V3的另一个改进之处就是多尺度检测,借鉴了FPN(Feature Pyramid Networks)的思想,来提高对小尺度物体的检测效果。下面以$608* 608$ 的输入图像来分析一下YOLO V3中的三种尺度。
- Scale 1:在基础网络之后(79层)再添加一些卷机层得到预测结果,下采样倍数为32,得到输出的张量大小为$19* 19$。下采样倍数越高,对应的感受野(Receptive Field)也就越大,因此适合检测图片中尺寸比较大的对象;
- Scale 2: scale 1中未经过卷积层的特征图($19* 19$)在上采样($* 2$)之后通过
concat和第61层(最后一层输出为$38* 38$的layer)的输出拼接,再通过多个卷积层得到预测结果。Scale 2 的下采样倍数是16,特征图尺度相比sacle 1变大一倍,适合用来检测图片中中等尺度的对象; - Scale 3:用同样的方法,scale 2 中未经过卷积层的特征图($38 * 38$)上采样之后与36层的输出($76 * 76$)进行拼接,在通过多层卷积得到预测结果。Scale 3的下采样倍数是8,特征图尺度相比scale 2变大一倍,它的感受野也是最小的,适合于检测图片中小尺寸的对象。
作者在论文中也提到了为什么要把小尺度的特征图和和前序网络层次的输出进行拼接,这种方法使我们能够从上采样的特征图中获得更有意义的语义信息,并从早期的特征图中获得更细粒度的信息。
3. Bounding box prediction
YOLO V3沿用了V2中用Kmeans聚类先验边界框(Bounding Box Prior)尺寸的方法,V3中选用K=9,在数据集上总共聚类9种尺寸的先验框,每种尺度的特征图设定3种尺寸。(10 * 13),(16 * 30), (33 * 23), (30 * 61), (62 * 45), (59 * 119), (119 * 90), (156 * 198), (373 * 326)。
对于最小的特征图$19 * 19$,应用最大的先验框(119 * 90), (156 * 198), (373 * 326),因为其具有最大的感受野;对于中等大小的特征图$38 * 38$,应用中等大小的先验框 (30 * 61), (62 * 45), (59 * 119);对于最大的特征图76 * 76的特征图,应用最小的先验框(10 * 13),(16 * 30), (33 * 23)。
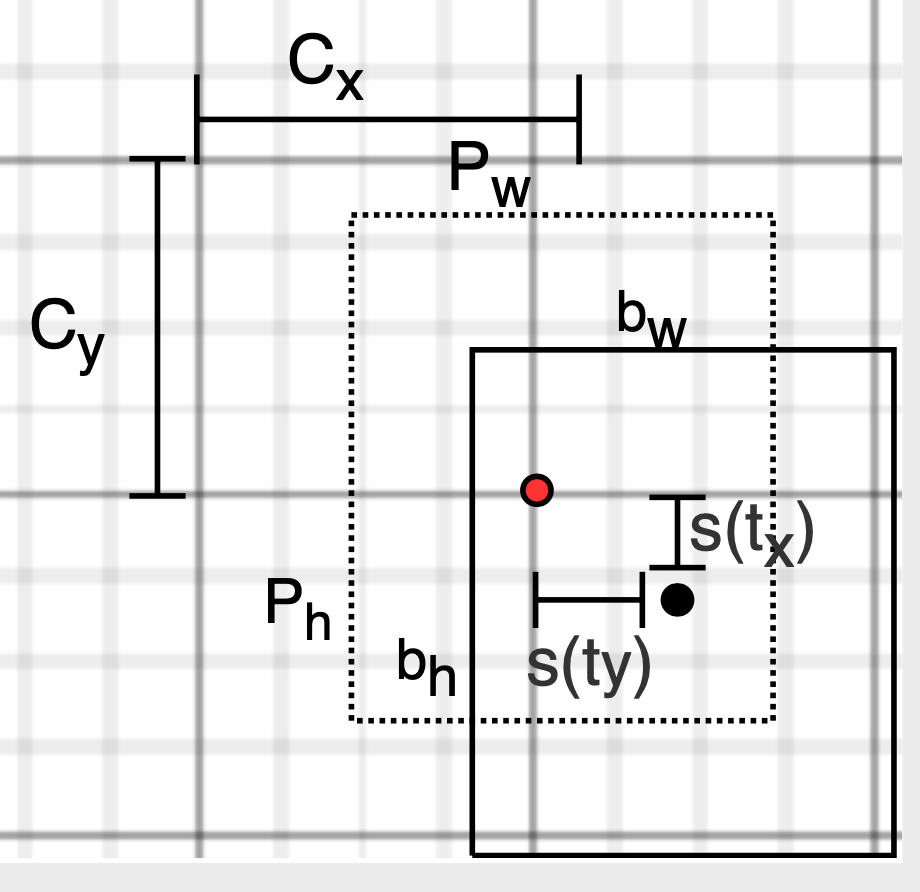
在YOLO V3中,每个尺度的特征图中的每个格子都会预测3个B-Box,包含边框的位置(x, y, w, h)、object confidence 和80个类别的概率,$N* N *[3 *(4+1+80)]$。例如,对于scale 1,输出结果为$19 * 19 * [3 * (4+1+80)]$。V3在对边框进行预测的时候,采用的是Logistic Regression,LR用于对先验框包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。如果一个先验边界框与真实对象的重叠量大于任何其他先验边界框,则该值为1;如果先验边界框不是最好的,但是与真实对象的重叠量超过某个阈值(V3用的0.5),这个先验框将会被忽略,不会进行预测。这一步是在预测开始之前进行的,V3只会对一个先验框进行操作,也就是最佳的先验框,这样可以去掉不必要的先验框,减少计算量。
如上图所示,图中的虚线框为Kmeans得到的先验框,实线框是通过YOLO V3预测的偏移量计算出来的预测边界框。其中,$(C_{x},C_{y})$ 是先验框在特征图上的中心坐标,$P_{w},P_{h}$是先验框的宽和高;$(t_{x}, t_{y})$ 是预测边界框中心相对于先验框的中心的偏移量, $t_{w}, t_{h}$ 是预测边界框的宽高缩放比;$(b_{x}, b_{y}, b_{w}, b_{h})$ 是最终预测的目标边界框的绝对位置和尺寸,$\sigma(x)$是Sigmoid函数(在图中用s(x)表示),其目的是将预测的中心偏移量约束到0和1之间,保证预测的边界框的中心坐标在一个cell当中。通过下面的公式便可计算得到预测边框的位置和尺度。
4. 损失函数
关于YOLO V3的损失函数论文里面少有提及,只有V1的论文里面列出了明确的损失函数公式。总体而言,V3的损失函数还是由三部分组成:目标置信度损失,目标分类损失和目标定位损失。但其中的一些细节方面还是做了改进。
4.1 Objectness confidence loss
目标置信度可理解为预测框内存在目标的概率,目标置信度损失$L_{conf}(o,c)$采用二值交叉熵(binary cross-entropy),其中$o_{i}\in\{0,1\}$ 表示预测的边界框中是否含有目标,$o_{i} = 0$表示不存在,$o_{i} = 1$表示存在。$\hat{c}_{i}$表示预测边框 $i$ 內是否存在目标的Sigmoid概率。
由于V3只会对一个先验框进行操作,如果一个先验框未被分配给任何一个目标对象,那么这个先验框就不存在定位和分类损失,只存在目标置信度损失。
4.2 Classification loss
目标类别损失$L_{class}(O,C)$同样采取二值交叉熵损失,作者在文中提到这样做是应为一个可能属于多个类别,例如一个人同时属于“人”和“男人”两个类别,使用Softmax的时候会假设每个预测框中的对象只属于一个类别,但事实往往不是这样的。但这个也要分具体的使用场景,如果训练数据中每个目标只有一个标签(只属于一个类别),也许不使用二值交叉熵也能有很好的效果。$L_{class}(O,C)$中 $O_{ij} \in {0,1}$表示预测边框 $i$ 中是否正式存在目标属于第 $j$ 类,0表示不存在,1表示存在。$\hat{C}_{ij}$ 表示预测边框 i 內是否存在第 j 类目标的Sigmoid概率。
4.3 Localization loss
目标定位损失$L_{loc}(l,g)$采用真实偏差值与预测偏差值的差的平方和,其中$\hat{l}$ 表示预测边框与先验框(bounding box prior)之间的坐标偏移量(注意网络预测输出的是偏移量,而不是觉得位置),$\hat{g}$ 表示预测边框相对应的真实边框(ground truth box)与先验框之间的坐标偏移量。$(b^x, b^y, b^w, b^h)$ 为最终预测边框的参数(位置和尺寸,不是偏移量),$(c^x, c^y, p^w, p^h)$为先验框的参数,$(g^2, g^y,g^w,g^h)$为与预测边框匹配的真实目标矩形框的参数。
5. 总结
看完网上的帖子,写完blog,基本上解答了我在读论文的时候产生的一些疑问。
如何得到先验框?
通过Kmeans聚类得到9中尺寸的先验框,每种尺度特征图分配三种尺寸的先验框。另外在用Kmeans的时候需要用到距离,常用的是欧式距离,但这里对于两个B-Boxes 来说怎么算距离呢?有网友指出利用IOU来算距离,但因为还未看源码,所以不确定是否是这样的。
$d(box, centroid) = 1 - IOU(box, centroid)$
如何通过先验框预测得到预测边框?
详见第三部分Bounding Box Prediction。
如何提取不同尺度的特征图?
详见第二部分。另外附上感受野的定义:
The receptive field is defined as the region in the input space that a particular CNN's feature is looking for or is affected by.二值交叉熵(Binary Cross-Entropy)是如何定义的?
$BCE = - \sum(t_{i}* logs_{i})= -t_{1}* logs_{1} - t_{2}* logs_{2}$
where:$t_{1}\in \{0,1\}$ is the ground truth for C1, $s_{1}$ is the score for C1;
$t_{2}=1-t_{1} $ is the ground truth for C2, $s_{2} = 1 - s_{1}$ is the score for C2.
虽然YOLO V3在多尺度对象检测上有较好的表现,但使V3很难是边框和物体很好的对齐。
参考
- https://blog.csdn.net/qq_37541097/article/details/81214953
- https://blog.csdn.net/leviopku/article/details/82660381
- https://mp.weixin.qq.com/s/E12qr8Z4PkeBE7B90A8Tvg
- https://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247492506&idx=1&sn=29f504cbdfb32691debf73aec9153839&chksm=ec1c0e63db6b8775e4c9ecd9c38566a84812cd558f88dc1473c931bda53160270d2719b7b097&scene=21#wechat_redirect
- https://www.cnblogs.com/ywheunji/p/10809695.html